Riding the Machine Translation Hype Cycle – From SMT to NMT to Deep NMT by Dion Wiggins
 There is a running joke in the translation industry that machine translation will be a solved problem in 5 years. This has been updated every 5 years since the 1950’s. The promise was always there, but the technology of the day simply could not deliver.
There is a running joke in the translation industry that machine translation will be a solved problem in 5 years. This has been updated every 5 years since the 1950’s. The promise was always there, but the technology of the day simply could not deliver.
However, there has undoubtedly been progress. When we started our company over 10 years ago, MT was considered a joke and ridiculed. At the time, we looked to purchase MT technology, but were unable to find any technology that could rise to the challenges that we needed to address. At the time we had the formidable task of translating all of Wikipedia and other high volume and very mixed content domains from English into mostly second or third-tier Asian languages.
To find a way to address that problem, we flew in Philipp Koehn to introduce him to our concepts and ideas. Philipp at the time was a promising researcher in Statistical Machine Translation (SMT) and recently created a large corpus of bilingual content derived from European Parliament documents and had just released the first version of the Moses SMT decoder which in the meantime has become the de-facto platform for SMT. Soon after, Philipp joined our team as Chief Scientist and has been driving research and development efforts ever since. Philipp joining the team gave us the in-depth knowledge of MT that few had at the time and allowed us to stay ahead of the competition from a technical perspective. While Philipp was the father of the Moses decoder, his Master’s thesis in the 1990’s was on Neural Networks before they become practical for machine translation.
The hype about Neural Machine Translation (NMT) and Artificial Intelligence (AI) has hit a new peak in the last year, with claims from Google and others that translations produced by their MT technology is difficult to distinguish between human translation. This has raised eyebrows, with some impressed, some in laughter and as expected a lot of skepticism. Riding on the wave of attention and hype surround NMT and AI are a number of companies that claim to deliver products or solutions that leverage the latest and greatest approaches, some of whom are established and some new to the space. One of the more recent launches has attempted ride the hype wave by claiming to beat Google and many other large number claims that to most sound great, but lack any real meaning once you dig a little deeper and understand more fully the claims. In making such claims, the next wave of hype that MT is so often criticized for has been reignited, and perhaps even relaunched. The next wave of hype is going to be deep learning AI and in the case of machine translation that is known as Deep NMT. Today there are a handful of MT vendors, such as Omniscien Technologies, who are delivering Deep NMT commercially as compared to those offering NMT. Expect there to be some confusion around the difference between NMT and Deep NMT for some time.
But before we get too excited about claims of great quality and all the other usual types of marketing and counter statements that go along with each wave of MT quality hype, let’s take a more pragmatic view of MT and how to read the hype, understand the issues and ask the right questions.
Machine Translation Quality
Type of statements that will be/have been made:
“3 out of 4 human translators liked us more than another MT provider.”
“We scored better on the BLEU metric than another MT vendor.”
“…almost impossible to distinguish between machine and human translations”
These statements are vague and often misleading. A group of 4 humans evaluating text is not at all meaningful. The margin of error is substantial and while it might be indicative, it is not scientific. But moving beyond the number of linguists in the sample, there are a number of other variables that are not transparent in such simplistic statements. There is usually no background or other information on the linguists their qualifications, biases (i.e. who they work for could change their views, mother tongue, domain expertise, skill level or what side of bed they got up on that morning. In other words, such vague and unqualified statements should be seen as nothing but marketing.
There are several ways to address this issue to make such statements hold water. First, qualifying who the linguists are that are providing their opinions on translation quality is important, as is the quantity of reviewers. In the example of 3 out of 4, just 1 more linguist deciding that the competing MT provider was better would make it 50%. The scope of a single or small number of opinions has too much impact on the confidence of the metric. The other key issue is the size of the content that was measured. Many very small, with as little as 100 sentences or less. With 100 sentences, there is a margin of error of 9.8%, which could easily swing scores in the direction of 2 out of 4 or 50%. Trying to pass off translation quality with a representation of an entire language with as little as 100 sentences is not realistic.
The problem with making such claims and failing to qualify them is that they can easily be countered by competition or others in the industry. As an example, after the recent launch of DeepL with some big but unqualified quality claims, Slator did an informal survey (https://slator.com/features/reader-polls-mt-quality-lsps-risk-databreach-universities/) which indicated only 28% preferred DeepL, with 28% preferring Google, 23% were unsure and 21% said it depends. This will happen nearly every time when these claims are made, as it did when Google made the big NMT announcement in 2016 claiming to be nearly indistinguishable from human translators.
A BLEU score is the most irrelevant metric if it is unqualified or used improperly, which unfortunately is too often. First and foremost, a BLEU score must be calculated from a truly blind test set. See https://omniscien.com/whitepapers/comparing-machine-translation-engines for a comprehensive list of criteria that need to be established to provide a solid and reliable metric. Additionally, it is not uncommon for NMT to score lower on the BLEU metric than Statistical and Rules-based MT, yet when reviewed by human experts, the NMT is more fluent and preferred. Automated metrics are very good as quality indicators, but to have full confidence the results should be verified by humans. That makes metrics like BLEU very useful for automated comparison, and engine training and analysis tasks, but less so if you want to know which translation output would be more acceptable in the real world. Where automated metrics such as BLEU are very useful and do not need to be verified by humans is when comparing the improvement of an individual engine over time. An increase in the score when comparing a newer version of an engine to an older version of the same engine will typically indicate a quality improvement. More on this a little later…
The source of test set being measured by any of these metrics is also very relevant and seldom qualified. NMT does very poorly when the test set is out of domain, while SMT handles out of domain content much better. Alternatively, NMT handles in-domain content generally better than SMT in the most common conditions. But in either case, if an engine is trained with data from the domain of the test set, it will have a bias to that domain and do better on this specific test set than another. As an example, if you put a hotel description into Google, you get a pretty reasonable translation in most cases. If you then change that to an engineering manual for a new kind of transport such as the hyper-loop you will find that it will typically be less useful. This is simply a matter of one set of data being more suitable than another set of data. As such, the test set and the training data need some level of qualification. It is equally easy to make the test set too close to the training data, which results in a recall instead of a translation. It is easy to make one MT provider look good and another bad and then invert the results by simply changing the domain data that is being measured. There is no single MT engine that can handle all domains well, which brings me to my next point…
What is the Main Purpose of the MT Provider?
Understanding the purpose of the MT provider dramatically changes the way in which quality is perceived and how translations are created. Google, Microsoft Translator, and new entrants like DeepL are trying to translate anything for anyone, any time. As such, by this mission, the MT engines must be trained on very large amounts of data to cover as many domains as possible. While this has some benefits, it also emphasizes several issues. When you translate something with a generic MT engine, you get whatever the engine decides is best based on their generic giant bucket of data. This usually means statistically best and considers only the individual sentence being translated to determine context rather than the entire context of the full text being translated. The sentence “I went to the bank” is a simple sentence, but depending on the context it is being used in, the meaning is very different. Consider the following 3 examples:
- The water was cold and the current strong. I went to the bank. My feet sunk into the mud.
- I had run out of cash. I went to the bank. It had just closed.
- I was in the lead of the last lap and the final turn. I went to the bank. The g-force pulled me down into the seat.
With the additional sentences surrounding “I went to the bank.”, it is possible to determine the context of “river bank”, “ATM” or “banking the car into the turn”, which is quite easy for a human. However, today that is not how MT works. MT engines currently only understand a single sentence at a time, with each sentence in the document often split across many machines in order to translate more quickly. In a generic system that is trying to translate anything in any domain, it is very easy for the machine to determine the wrong domain and translate it in the wrong context. This issue is very commonplace for MT providers that build very large all-encompassing MT engines.
Specialized MT providers, such as Omniscien Technologies, address this issue by building customized MT engines that are designed for a purpose and trained on a smaller set of specialized in-domain content. This often helps to resolve the issue known as Word Sense Disambiguation – where a word can have many meanings depending on the context of use. For example, if we customize an engine for the Life Sciences domain, then it will have been trained to understand the concept of a virus in the context of medicine rather than the context of a computer virus. When training an engine on data that is directly relevant to the domain, the engine has a deliberate bias towards that domain and as a result when translating in-domain content will produce a much higher quality, less ambiguous and in-domain translation. A frequent mistake is to think that more data is better, so data from other domains is mixed in. While this approach may help in some cases, it can easily result in creating the same issue faced by generic engines where data from multiple domains or even multiple customers data can conflict and bias an engine causing undesirable results.
Additionally, some MT providers further enhance the training data with data manufacturing and synthesizing. At Omniscien Technologies, we do this for all custom engines as a means to extend the data that a customer can provide us, which in turn delivers more in-domain training data for an engine to learn from. It is very rare that a customer has sufficient quantities (1 million+ bilingual sentences) of data needed for a high-quality engine with their data alone. This is where data manufacturing and synthesis comes in. Omniscien Technologies has developed a range of tools in this space that create both bilingual and monolingual data that is in-domain that leverages the customers data and domain to speed the process and build out as much as 1-2 billion words of content to further enhance an engine. While this process takes a little time, the results are a much higher quality in-domain engine. The resulting specialized engine is often fine-tuned for the correct writing style (i.e. marketing, user manuals, engineering, and technical document) which further increases quality and reduces editing effort. Additionally, platforms like Omniscien Technologies’ Language Studio™ are able to provide control features such as glossary and terminology, do-not-translates, formatting, and complex data handling that is not provided by a generic MT offering. Our ability to script rules in the translation workflow means that complex content such as patents and e-commerce can also be easily handled.
The net result of a customized and in-domain engine is that almost every time the engine is much higher quality than Google or other generic/translate anything kinds of MT engines. The negative of this approach is that it does require some effort to customize, which is taken on in the case of Omniscien Technologies by a team of linguistic specialists, and there is a resulting short delay while customization is occurring before you can begin translating. Additionally, if you were to then try and translate something out of domain (i.e. sending a document that discusses computer viruses into an engine trained for life sciences) the resulting translation would be out of context and thus lower quality. Just like a human with specialist domain skills, a trained and specialized MT engine will always produce a higher quality translation than a generic one-size-fits-all solution.
Traveling Hype Waves – SMT to NMT to Deep NMT
So now that we understand some of the key issues around the hype and the differences, capabilities, and purpose of generic vs. specialized MT providers and MT engines, what should we expect next? Our Chief Scientist, Professor Philipp Koehn is very optimistic on the ongoing progressive improvement of MT technology and has worked with our team to constantly improve our offerings. In the last year, our training time for NMT has dropped from 1 month to 1 day and our translation speeds on a single GPU have increased from 3,000 words per minute to 40,000 words per minute. These are progressive improvements that make technologies such as NMT more commercially viable and practical for real-world use. Waiting a month for an engine to train is not very practical. Waiting a single day makes a notable difference in many areas, including how often an engine should be retrained and improved. But as we head into Deep NMT, training times are again extending from the 1 day of NMT to 5 days. This is still practical as even a large SMT engine can take almost as long to train, but is it worth the additional wait and what will Deep NMT bring that is not available in NMT or SMT?
One of the reasons that neural networks are in fashion now again, after their last peak in the 1980s/1990s, is that modern hardware allows the stacking of several layers of computing. This is known as deep learning. Just like longer sequences of instructions of traditional computer programming code allows for more elaborate algorithms, so do several neural networks layers allow for more complex processing of input signals. In the case of deep neural machine translation, several layers of computation enable more complex processing of the input words to separate out their distinct senses. The deep neural machine translation system of Omniscien Technologies uses several layers in the encoder (to better understand input words) and in the decoder (to be better aware of long-distance interactions between words).
In a recent project designed to compare NMT and Deep NMT technologies, we trained 2 language pairs (English > Japanese and Japanese > English) on a deliberately limited (~1 million segments) set of training data in the life sciences domain. The test set was verified as a blind test set (not in training data, but in-domain) and each engine was trained on the identical data, with the only difference being the technology used to train the engines. We also included metrics from Google and Bing as a further comparison to compare against a specialized MT engine vs. a generic MT engine.
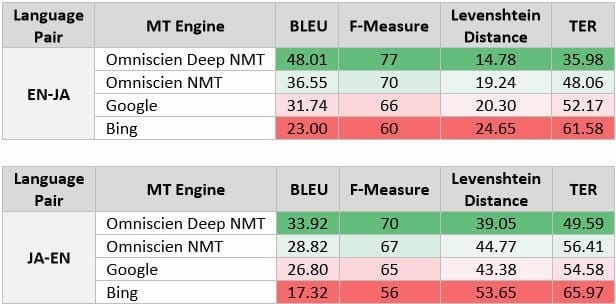
The above metrics demonstrate the following:
- Even on a limited amount of data (~1 million segments), a specialized engine trained on in-domain data can easily outperform a generic MT engine such as Google or Bing that is trained on much larger quantities of data (billions of words). This shows that the quality and domain suitability of the data is much more important than the volume of data.
- Although the training data was identical, the improvement when switching from NMT to Deep NMT is notable. In the case of EN-JA, the BLEU score increased by 11.46 points and JA-EN the BLEU score increased by 5.1 points.
- Language pair and direction matter. Although both EN-JA and JA-EN were trained on the identical data, the score improved notably more for EN-JA than JA-EN.
- Had this test not been limited to ~1 million segments, and more in-domain data added, the quality difference would have been even higher than what is shown in the above table.
Further extending this analysis, Google has included patents from English and German as part of its training data, but also includes a wide variety of other data. Omniscien Technologies has trained engines exclusively on patent data with approximately ~12 million segments of a bilingual sentence. The comparison in the table below shows clearly that the focus on a specific domain delivers a notably higher quality translation result than mixing wide varieties of data.
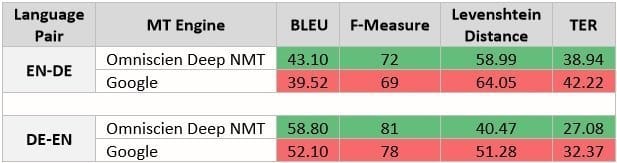
Bottom Line
There are several key takeaways from this blog post:
- Expect the hype on MT to increase with some focus moving to Deep NMT. Sometimes it will be a technological advance that should be easily validated and proven, but in many others, it will be just hype and marketing.
- Expect some offering NMT to claim they are delivering deep learning or Deep NMT. We have seen some MT vendors that are confusing the market by making such claims.
- Any real claim of quality will eventually be verified either formally or informally by third parties. After so much hype for so long, anyone making quality claims should be prepared to have those claims independently verified.
- Generic MT (irrespective of the technology used) can be easily and consistently beaten by a specialized custom engine trained with in-domain data, even when the quantity of data is quite limited.
- Lack of control of terminology, vocabulary, and simple business rules is a limiting factor for generic MT, and specialized MT vendors will vary in their support for features that allow control.
- There are many MT providers that are doing little more than putting a “pretty” interface over the top of open MT toolkits such as OpenNMT and Moses. This allows people to make MT engines, but not necessarily make high-quality MT engines as many other features such as data manufacturing and synthesis are not available. Do-It-Yourself MT suffers the same fate – it implies you know how to do it yourself. Specialist skills and technologies are necessary in order to deliver optimal quality.
- More data is not the solution to high-quality MT. The right data that is focused on solving a problem is the solution. This data can be provided by a customer or manufactured/synthesized.
Ultimately while machines may produce MT, humans are going to decide how useful it is. The ultimate definition of translation quality is “whatever the customer says it is”. The MT must be suitable for the customer’s purpose. Haggling over whether one generic MT is better over another ignores the most important factor in that of the suitability of the MT for the desired purpose by the consumer of the MT. The quality of MT to meet customer requirements is determined by understanding that purpose and customizing an engine to meet that requirement.