When, Why and How to Migrate from Statistical to Neural Machine Translation by Dion Wiggins
 It has long been established that a customized for-purpose machine translation engine will deliver higher quality translation output with a relatively small amount of training data compared to a generic MT engine such as Google. But with the advances brought about by Neural Machine Translation (NMT) and Deep NMT engines, the results even from generic engines are notably better than the preceding SMT technologies. But what about customized MT engines? Are they still good enough to beat Google and other generic engines? Should SMT engines be upgraded or replaced by NMT/Deep NMT engines altogether?
It has long been established that a customized for-purpose machine translation engine will deliver higher quality translation output with a relatively small amount of training data compared to a generic MT engine such as Google. But with the advances brought about by Neural Machine Translation (NMT) and Deep NMT engines, the results even from generic engines are notably better than the preceding SMT technologies. But what about customized MT engines? Are they still good enough to beat Google and other generic engines? Should SMT engines be upgraded or replaced by NMT/Deep NMT engines altogether?In my earlier blog post “Riding the Machine Translation Hype Cycle – From SMT to NMT to Deep NMT”, I showed conclusively that the same rules apply to NMT and Deep NMT engines that applied to SMT engines. Higher quality data that is domain-specific will deliver much better results than a generic engine can produce.
So, is it a simple case of “Take the data I prepared for my SMT engine and use it directly in my NMT / Deep NMT engine”? – Not so fast. It is not quite that simple. There are several notable differences.
Language Model
SMT uses target language data to act as a type of filter so that low scoring phrases are not selected for the final output. This target language data is referred to as a Language Model and is in addition to the target language data that is included in the bilingual data. As target language data is monolingual, it is much easier to source in-domain content in larger volumes, often millions or even billions of words.
NMT does not have the same language model concept and instead builds a sort of language model from the bilingual training data. Bilingual data is the only data used today in the leading NMT engine algorithms.
Data Quality
SMT is a lot more tolerant of data quality issues. Additionally, SMT engines can be “hacked” if bad data is found after training, and the bad data can be removed surgically without having to retrain the entire engine. This is ideal in cases where perhaps two words are glued together in the training data or there are some bad characters in the data, but it is not suitable when the quality of the translation is poor.
NMT requires higher quality training data than SMT. Once an NMT engine has been trained, if bad data is found, the entire engine must be retrained to remove the bad data. More data can be added with an incremental training to overpower the flawed data, but this is not always practical.
In our Language Studio™ platform we have implemented a feature for both SMT and NMT that is able to block “bad” words and phrases from being selected in the output. “Bad” words can simply be specified in a list and they will never appear in the output. This helps to overcome some of the simpler cases that would normally require “surgery” or retraining.
Data Quantity
Although a typical SMT engine can be trained on as little as a few hundred thousand bilingual segments and a good dictionary in order to achieve a basic level of quality, the minimum volume of data required for an NMT engine is about one million bilingual segments of in-domain data.
A typical SMT engine will range in data size from 1-8 million segments, with a large engine as much as 20 million segments. On the other hand, a typical NMT engine starts at 20 million segments of in-domain data and goes up into hundreds of millions of segments.
Few client companies have ever had anywhere near these volumes of data. In 10+ years of business, we have only encountered perhaps 3 or 4 companies with such volumes. For this reason, Omniscien Technologies has developed techniques and technologies to manufacture and synthesize in-domain data in large volumes. This helps to bridge the data gap for both SMT and NMT technologies, making them viable where they may not have been previously.
In-Domain Data
With SMT you could get away with a small volume of in-domain data applied on top of a larger volume of general data for a language pair. A good in-domain dictionary and in-domain language model would go a long way to creating a better engine.
NMT, On the other hand, requires not only more data of higher quality, but the data must be in-domain, which makes the goal of collecting 1 million+ segments even more difficult to achieve. Data manufacturing and synthesis are possible in many but not all cases.
NMT Intolerant of Out-of-Domain Translation Input
SMT will still give some semblance of quality when the translation input is out-of-domain. By contrast, NMT will simply give up when content is too far out-of-domain and just produce gibberish that is not relevant at all.
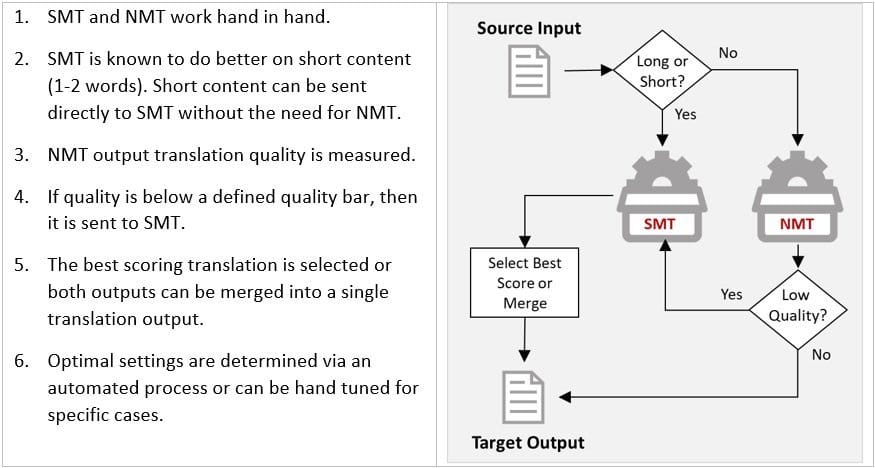
As it is not always possible to control input content, Omniscien Technologies designed a hybrid SMT/NMT model that combines SMT and NMT technologies. By using a proprietary confidence score algorithm, it is possible to determine out-of-domain or lower quality translation and then attempt to address the quality issue with SMT or a combination of SMT and NMT. This Hybrid SMT/NMT model has been shown to improve translation quality significantly overall and address the cases where submitted content is not a match to the domain of the data that the engine was trained on.
When
NMT may be a significant step forward in machine translation quality provided that certain criteria are met, but SMT may still be the best solution in many cases. When the volume of data available for a language pair is low, SMT is normally a better and more viable solution. It can be enhanced with a larger language model and a good dictionary quickly and easily. SMT may also be more suitable if you are starting with no data and building up your data volumes. It is possible to start with SMT and evolve to reach a base level of data maturity over time and then switch/upgrade to NMT gradually. As an example, iflix, one of Omniscien Technologies’ media customers who translate subtitles, started with no data at all in English to Vietnamese. As this was a new language pair for Omniscien too at the time, we had no data and had to acquire a small amount of data. Over a six-month period of MT post-editing and feedback, iflix produced enough in-domain content that they were able to train an NMT engine, which very quickly was able to beat the translation quality from Google Translate by a substantial degree.
When you have one million segments of data or you are able to manufacture and synthesize data that is in-domain to make up for the shortfall, then NMT may be a viable solution. There are many elements that go into determining if NMT will work for a particular dataset. Some type of content is more suited to data synthesis and manufacturing than others.
Why
There are 2 reasons to migrate from SMT to NMT. The most obvious is when NMT will deliver higher quality translation output. The second reason is the translation speed. A single CPU core translates SMT content at about 3,000 words per minute. While a single GPU using NMT translates at around 40,000-50,000 words per minute.
How
When building a Professional Custom MT Engine with Omniscien Technologies, an experienced custom MT engine project manager will analyze the available data, including the data in our repository as well as the data that a client is able to provide, and he can then build a tailored Quality Improvement Plan to achieve the best translation quality possible in the shortest amount of time. As Omniscien Technologies has been progressively building out 13 industry domain sets of data across more than 550 language pairs for several years, we are often able to complement a customer’s data with similar in-domain content, reducing the data barrier to entry. This combined with data manufacturing and data synthesis delivers high-quality engines in a short period of time. As part of the Quality Improvement Plan, the project manager will recommend a path to further improve the engine progressively over time. Incremental improvement training is low cost and can be done in as little as a couple of hours.
As noted above, NMT needs cleaner data than SMT. Omniscien Technologies pioneered an approach 8 years ago called Clean Data SMT. Language Studio™ has been enhanced to perform even more rigorous data cleaning and analysis for NMT and Hybrid SMT/NMT engines.
If you decide to migrate your SMT engine to NMT, here are the basic steps we recommend:
- Contact your Language Studio™ account manager about upgrading and they will guide you through the process.
- Export the TM used in your SMT engine.
- Check to see if you have any additional TM that is relevant to the same domain and language pair.
- Export the target language and source language (non-bilingual) data from your existing engine. This may be useful in data manufacturing.
- Upload the data to the newly created Hybrid SMT/NMT engine. Your account manager can also migrate this data across to the new engine for you.
- Finalize the Quality Improvement Plan with your project manager and then sit back. Depending on the data work needed, a brand-new engine can be created in just a few days or a couple of weeks. Heavy data manufacturing and data synthesis takes a little longer than just processing and leveraging the data that is on hand. Of course, if you provide sufficient data, the cleaning and training process can take as little as a couple of days.
Bottom Line
While it is not as simple as outright reusing the SMT data for NMT as one would initially expect, Omniscien Technologies’ team has created a fine-tuned and proven approach that makes the process of migrating from SMT to NMT straight forward and removes many of the risk factors. Our experienced project managers will guide you through a standardized process that creates a tailored custom MT engine that is optimized specifically for your purpose.